
Porque a história importa sim!
Era uma vez um professor de informática que dizia que falar sobre a história da informática era irrelevante e iria passar rápido pela matéria. Só estava fazendo isso porque estava no currículo. É claro que eu tive de discordar. Conhecer a história nos dá uma compreensão melhor de como chegamos até aqui. As coisas nem sempre foram iguais. Muita gente esquece que as coisas mudam, olhar tudo em perspectiva nos faz entender melhor o mundo onde vivemos. Tem gente que se esquece, por exemplo que a prova de que a terra não é plana não veio de uma conspiração da NASA e sim da primeira circunavegação em 1521. Ou que os primeiros computadores surgiram na II Guerra Mundial. Se temos mais de 80 anos do surgimento do ENIAC, muita coisa mudou de lá para cá e alguns episódios curiosos nos fazem entender como chegamos aqui e nos dão algumas pistas do que pode acontecer num futuro não muito distante.
Os primeiros computadores
Trabalhar com grandes volumes de informações é um problema da civilização moderna. Organizar um conjunto de livros numa biblioteca ou o estoque de produtos de uma grande loja envolve catalogar, armazenar e ordenar um grande volume de informações. E chega um momento que um grande arquivo de metal não dá mais conta do recado.
Foi assim que algumas tecnologias modernas surgiram. A grande IBM surgiu com máquinas para processar o censo populacional dos EUA.
O uso dos bancos de dados em computadores teve que esperar um bocado. No começo, os primeiros computadores eletrônicos da década de 40 (houve algumas tentativas de computadores mecânicos e também eletromecânicos antes) como o Z3 na Alemanha, o Colossus na Inglaterra e o ENIAC nos EUA ainda utilizavam válvulas, tinham uma memória RAM muito limitada e não havia armazenamento em meios magnéticos da forma que conhecemos hoje, sejam fitas ou discos. O que havia nesta época eram os cartões perfurados e alguns tambores magnéticos. Sendo assim, trabalhar com grandes volumes de dados ainda era algo muito complicado.
Os primeiros bancos de dados
No final da década de 50 a IBM lançou os primeiros discos rígidos do mercado. Para se ter uma ideia, os discos do IBM 350 RAMAC tinham o tamanho de duas geladeiras, pesava quase uma tonelada, tinham capacidade útil de menos de 4MB e uma durabilidade de 3 mil horas de uso. O desenvolvimento dos discos rígidos na IBM foi inicialmente tímido, uma vez que ela estava ganhando muito dinheiro vendendo sistemas com cartões perfurados ainda. Ao mesmo tempo, na década de 60 os mainframes e também os “mini computadores” conquistaram o mundo dos negócios em grandes empresas e no governo. Logo surgiu uma grande demanda pelos discos rígidos e eles se tornaram mais rápidos, menores, com maior capacidade, mais confiáveis e mais baratos.
COBOL
Da mesma forma, no final da década de 50 surgiu a primeira linguagem de programação voltada para o o mundo dos negócios: o COBOL. O COBOL trabalhava com dados num formato posicional, onde os dados eram numerados numa tabela na qual cada campo ocupava um número fixo de caracteres. O COBOL teve enorme impacto na informática apesar das críticas. A sua forma de trabalhar com dados permitiu que aplicações trabalhassem com um grande volume para a época, mas todo o trabalho no controle dos dados era feito diretamente pela aplicação escrita em COBOL, não havia um sistema gerenciador de banco de dados.
O IDS (Integrated Data Store) foi o primeiro sistema gerenciador de banco de dados escrito para o COBOL criado em 1964 e utiliza assim como nos programas em COBOL o esquema de armazenamento em rede. Os bancos de dados em rede feitos para COBOL foram muito populares em mainframes e mini computadores até meados da década de 80.
IBM IMS
No final da década de 60, a IBM novamente entra no jogo para atender uma demanda da NASA, o banco de dados de partes e peças do projeto Apollo. Para isso, cria o IBM IMS (Information Management System) em 1966, com um esquema de armazenamento hierárquico, diferente do COBOL. O IMS tem longa vida dentro da IBM. A última versão do IMS foi lançada em 2015, ou seja, mais de 51 anos depois e continua sendo utilizado até hoje.
Nascem os bancos de dados relacionais
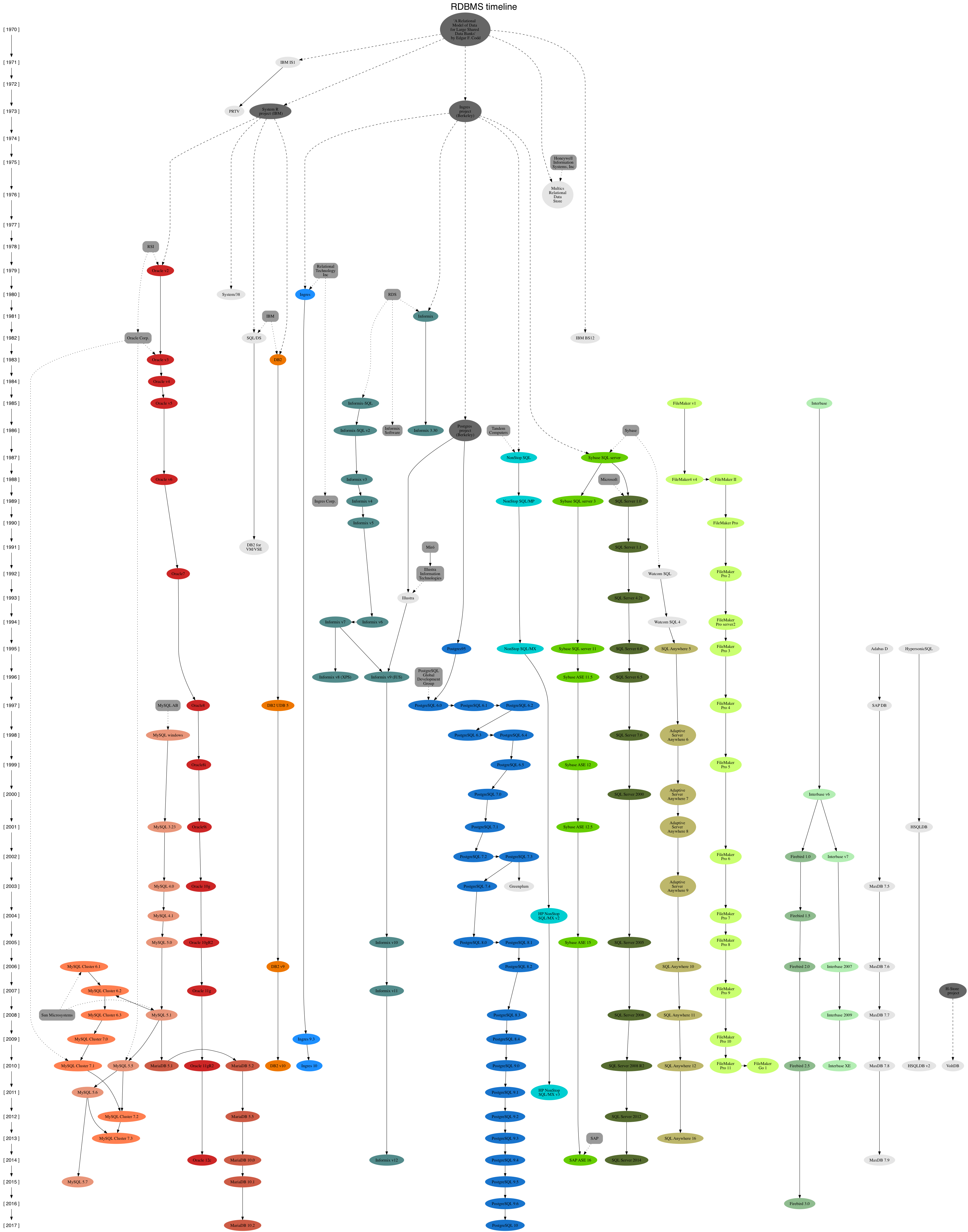
Enquanto a IBM estava investindo no IMS, em 1970 um de seus funcionários, o Sr. Edgar F. Codd, publica um documento intitulado “A Relational Model of Data for Large Shared Data Banks” descrevendo a teoria relacional. A IBM não deu muita bola para o trabalho do Sr. Codd. No entanto, algumas pessoas de outros escritórios da IBM gostaram das ideias e criaram os protótipos IBM IS1 entre 1970 e 1972, o IBM PRTV em 1973 e ainda o IBM BS12 em 1978 (este último chegou a entrar em produção por alguns anos). Fora da IBM, também surgiram outras experiências como o Ingres em 1973 e o MRDS em 1976.
IBM Db2
No entanto, foi em 1974 que a IBM cria um projeto chamado System R, para testar as ideias de Codd, no escritório de San José, Califórnia, onde o Sr. Codd trabalhava. Por incrível que pareça, o projeto não foi fiel às ideias do modelo relacional e foi deste projeto que surgiu a linguagem SQL. Isso foi motivo de muitas críticas à linguagem SQL, por ela não ser estritamente relacional. O System R foi comercializado pela primeira vez em 1977. Em 1981, foi lançado como IBM SQL/DS mas só em 1983 foi lançado o Database2 ou IBM Db2. O Db2 é até hoje o principal banco de dados em mainframes e utilizado principalmente por grandes instituições financeiras para bases transacionais de alta concorrência.
Ingres
É claro que a IBM demorou muito para lançar o Db2. E é claro, também, que o peso de tudo que a IBM lança no mercado tinha um peso enorme. O Ingres, criado nos laboratórios da universidade de Berkeley em 1973, criou a linguagem QUEL, baseado os trabalhos de Codd. Os próprios desenvolvedores do System R admitem que o QUEL era superior em vários aspectos em relação ao SQL. Mas o padrão de mercado se tornou a linguagem SQL e o QUEL, mesmo lançado 10 anos antes do DB2, não conseguiu superar o SQL. Apesar disso, como era um projeto com licença de software livre (a licença BSD da universidade de Berkeley), vários outros bancos de dados foram criados na década de 80 baseados no Ingres, entre eles o Sybase e o SQL Server. Em 1980, a Relational Technology, Incorporated (RTI) é criada para comercializar o Ingres. Em 1990 a ASK compra a empresa que por sua vez é comprada pela Computer Associates em 1994. Em 2006, o Ingres tem o código fonte aberto pela Computer Associates e em 2011 é comprada pela Actian Corporation.
Oracle
A Oracle, começou os trabalhos na mesma época, mas derivou seu banco de dados diretamente dos trabalhos do Ingres e do System R. A ideia era fazer uma versão compatível com o System R, mas não foi possível, pois a IBM escondeu alguns detalhes da implementação como os códigos de erro. Apesar de lançar sua primeira versão 5 anos depois do Ingres, utilizaram a linguagem SQL que futuramente se tornaria a linguagem padrão para os bancos de dados relacionais. A primeira versão (chamada de v2, por uma questão de marketing) foi lançada em 1979, mas foi só em 1983 com o lançamento da v3 e a reescrita do Oracle na linguagem C que ele começa a se tornar viável e ganhar o mercado, junto com uma campanha agressiva de marketing, claro. Na metade da década de 80, a Oracle derruba o seu maior competidor o Ingres. Em 1992, com a versão 7 a Oracle assume contornos mais conhecidos na maioria dos bancos de dados relacionais atuais com a implementação do PL/SQL, gatilhos, Foreign Keys, particionamento de tabelas e as consultas paralelizadas.
Em 2008 a Oracle firma uma parceria com a HP e lança o Exadata, integrando o hardware e software num único produto com alta performance e inovações na relação entre storage e banco de dados. Em 2010 a Oracle compra a Sun e passa a desenvolver o Exadata sozinha, sem a HP. Em 2013 a Oracle cria sua própria nuvem, porém ainda se encontra muito atrás dos seus principais competidores: Amazon, Azure e Google.
Hoje, o valor de mercado da Oracle é maior que o da própria IBM, sendo considerada a 6ª maior companhia de TI do planeta. Vale à pena lembrar que na década de 70 a IBM era disparada a maior companhia de TI do planeta.
Até breve…
- Na parte II iremos explorar um pouco dos anos 80 e 90, onde vamos comentar o padrão SQL, o surgimento do Teradata, dBase, Sybase, MS SQL Server, Postgres, MySQL, testes TPC e até sobre bancos de dados orientados a objeto.
- Na parte III vamos entrar no novo milênio com bases NoSQL e vamos especular um pouco sobre o futuro.
Observação: Para quem não sabe, a imagem no início do texto, é da unidade de discos do IBM RAMAC 350.
Atualização: Fiz algumas correções em 26/10/2017, agradeço aos comentários!


{kind=link}
Telles, eu estava sentindo falta de seus ótimos textos. Não pare por aí!
“Já em 1979, a Oracle já era superior ao System R”
Você usou Oracle em 1979? Não teve versão 1, apenas 2. Eu usei a versão 2 em 1982 em uma PDP-11 sob RSX-11. Foi escrito em linguagem de montagem do PDP-11 e era horrível. Só depois de termos a versão 3 no VAX em 1983, escrita em C, você poderia dizer que talvez era melhor do que o System R.
Relational Technology Inc., a empresa que comercializou o Ingres, foi fundada em outubro de 1980. A primeira versão comercial eu acredito saiu em 1983.
Antes dos discos rígidos, alguns computadores usavam tambores magnéticos para armazenamento secundário.
Correção: “linguagem de montagem” quiz dizer linguagem assembly.
Grade Joe! Muito obrigado pelos comentários. Sempre tive muita curiosidade sobre essa época do inicio dos bancos de dados relacionais. Infelizmente ainda era criança… Atualizei algumas coisas aqui. Você podia contar um pouco mais sobre as suas aventuras desta época…
Você vem para o PGConf Brasil 2018?
Detalhe: o IBM BS12 foi produção, não apenas protótipo.
Obrigado por trazer historia e agregar valor ao nosso conhecimento!
Indo para o 2ª (: